What will you learn in this section?
- Overview of the Boosting Model
Boosting is another ensemble model where weak learners are trained sequentially. Due to its sequential nature,
training time is slightly higher compared to bagging models. Boosting typically uses decision trees as base models.
These decision trees are generally numerous (50-200) and have very shallow depth. Shallow-depth trees are prone to
underfitting, leading to high bias and low variance. By combining these weak learners, boosting addresses the
underfitting problem.
There are several boosting algorithms, such as AdaBoost and XGBoost. Here, we will provide a brief overview of AdaBoost.
AdaBoost is a sequential boosting model that aims to correct errors made by previous models. The diagram below illustrates
the steps involved in the modeling process.
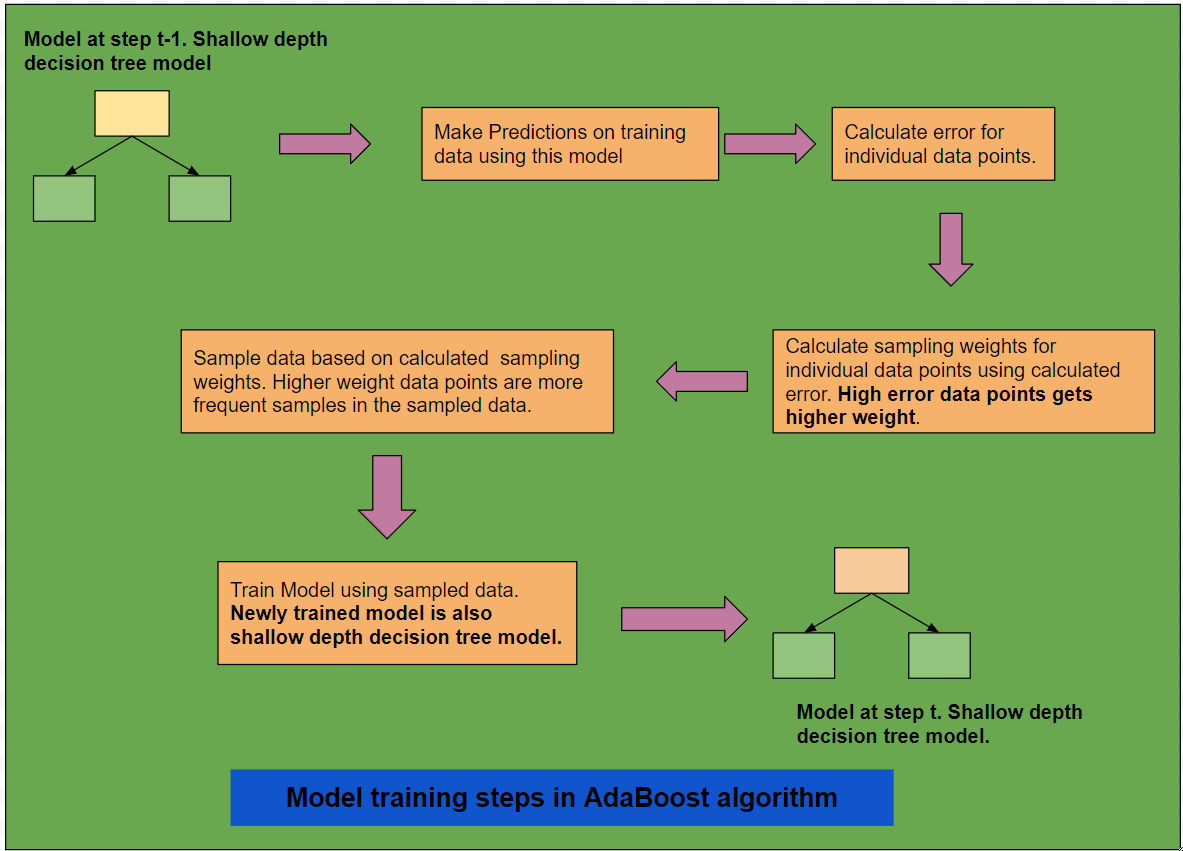
Diagram 1: Brief Overview of the AdaBoost Model
At any step \( t \), the model from the previous step (\( t-1 \)) is used to calculate the error for individual samples in the training dataset.
Based on the calculated error, the algorithm assigns weights to each sample. Higher error samples receive higher
weights. These weights are then used to sample data for training the model at time step \( t \). Since higher-weighted
samples had larger errors in the previous model, the new model at step \( t \) focuses on correcting those errors through sampling.
Once training for all models is complete, they need to be combined.
How AdaBoost Combines Models for the Final Prediction
AdaBoost calculates a weight factor for each model based on its average error. The weight factor is determined using the formula:
The final prediction is made by computing the weighted prediction from each model.
This discussion provides only a brief overview of the AdaBoost algorithm. Several details have been omitted for brevity. For an in-depth explanation of each step, you can refer to the AdaBoost discussion [add link].