What will you learn in this section?
- Details of the Stacking Ensemble Model
Stacking is one of the simplest ensemble learning strategies. In this approach, multiple heterogeneous models
are trained on the same dataset. Each weak learner typically exhibits a low bias and high variance problem.
By combining these weak learners, stacking effectively reduces variance and improves overall performance.
The core idea behind stacking is that different weak learners focus on different aspects of the training data,
capturing diverse patterns.
Major steps involved in the stacking algorithm:
-
Train multiple models using the same training data.
All the models in this approach are heterogeneous. Typically, 4-8 different machine learning algorithms are selected. These models may include KNN, Logistic Regression, Decision Trees, SVM, etc. Similarly, for regression tasks, appropriate models can be chosen.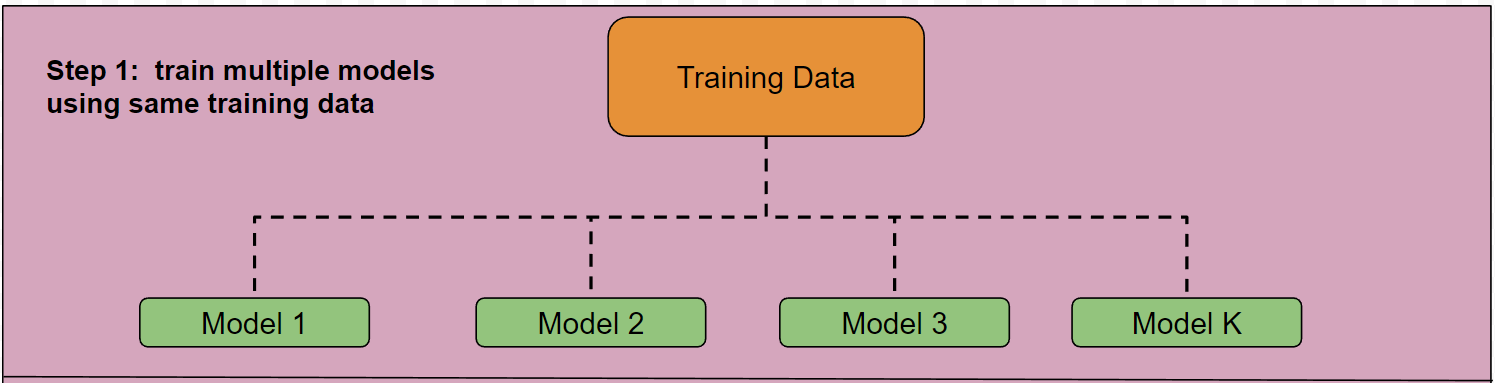
-
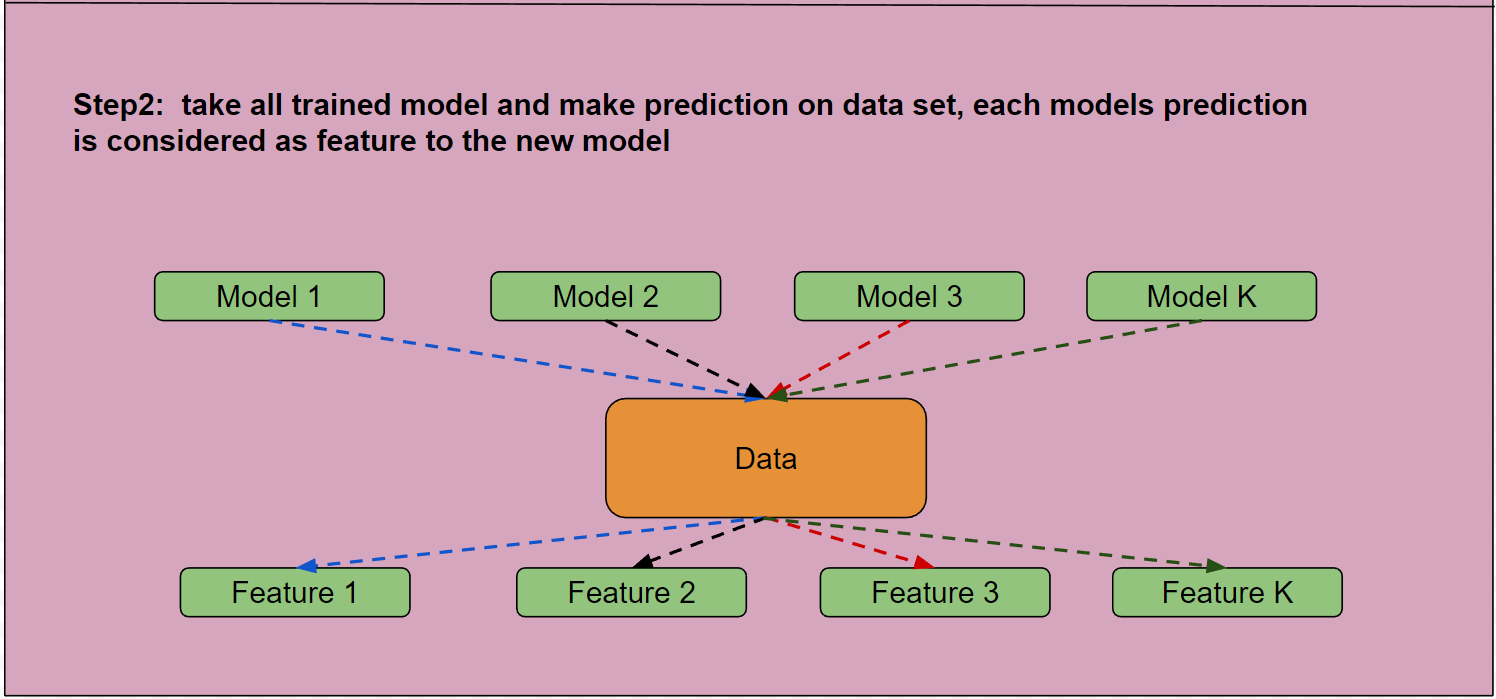
Use the trained models to make predictions on the dataset. The predictions from each model can be treated as new features.
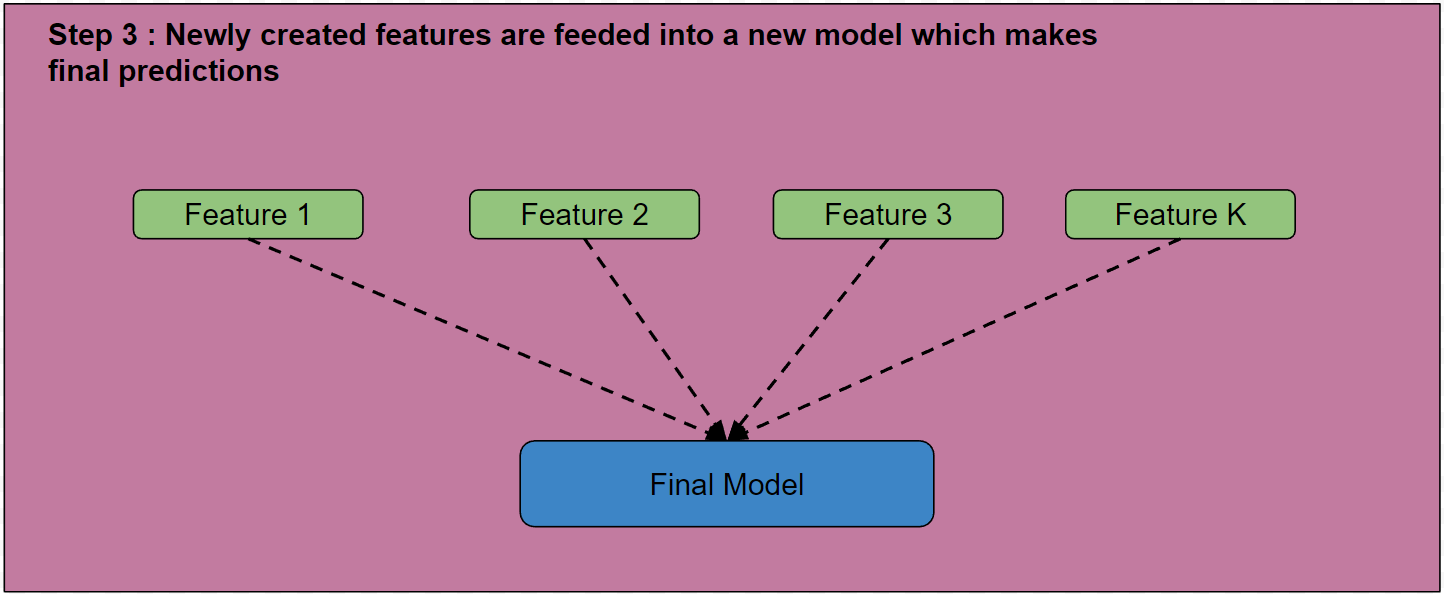
-
The newly created features are then used to train a final model, which makes the ultimate predictions.