Model Training
Once the dataset is ready, the next step is model training. Since we are working with text-only data, a good starting point is a TF - IDF based model. This approach is simple, fast to train, and often serves as a strong baseline for comparison. However, TF-IDF features are purely statistical, they represent how important words are within a document but do not capture any semantic relationships or contextual meaning between words. Because of this limitation, TF-IDF models are less suited for production scale applications where deeper text understanding is required.
A more advanced approach is to use Word2Vec embeddings for text classification. The general architecture for such a model is illustrated in Figure 1. The process starts by preprocessing and tokenizing the text data. Each token (word) is then mapped to its corresponding embedding vector using a pre-trained or learned embedding matrix. Once you have embeddings for all tokens in a post, these vectors need to be aggregated to form a single fixed-size representation for the entire post.
This aggregation can be done using average pooling or max pooling. In practice, max pooling often performs slightly better, as it tends to capture the most significant features from the text. After pooling, the aggregated embedding is passed through a few dense (fully connected) layers, followed by an output layer for classification.
For a binary classification problem like spam detection, the output layer will have a single neuron with a sigmoid activation function. For multiclass problems, the output layer will have as many neurons as there are classes, with a softmax activation to produce class probabilities.
Within the hidden dense layers, the ReLU activation function is generally preferred because it helps prevent the vanishing gradient problem and speeds up training. However, it's also worth experimenting with other activation functions such as sigmoid or tanh to see which performs best for your specific dataset and task.
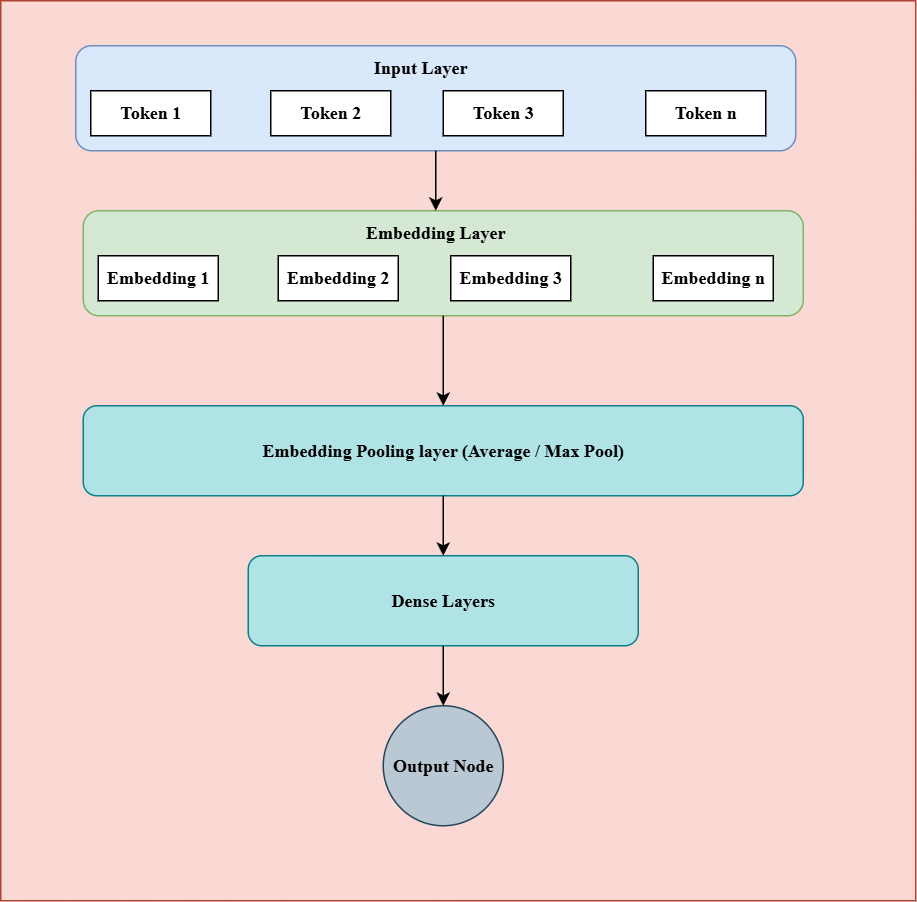
Figure 1: Word2Vec Embedding based model training.
At this stage, it's important to consider whether word order actually matters for the spam classification task. In many spam detection scenarios, the overall presence of certain keywords or phrases (like "free money" or "click here") carries more weight than their exact order. However, this may not always be the case, sometimes, the sequence of words can subtly change the intent of a message. It's a good idea to discuss this aspect with the interviewer and reason through whether incorporating sequential information would meaningfully improve model performance for the specific use case.
Models with sequence information
1. Positional encoding with Attention layer
To address this issue, we can modify the architecture to incorporate positional information. One simple way to do this is by adding positional encodings to the input layer, which help the model distinguish between word orders. Additionally, we can enhance the architecture by introducing a single head self-attention layer after the embedding layer and before the pooling step.
Figure 2 illustrates the detailed model architecture. The process begins by fetching embeddings for the input tokens and positional encodings to incorporate information about word order. These two representations are summed to get the final input representation and then passed through a self-attention layer, which captures relationships between tokens and produces a contextualized embedding for each one.
Since the attention layer outputs a representation for every token, we need an aggregation step to combine them into a single vector suitable for classification. A pooling layer , such as max or average pooling , is typically used for this purpose. The aggregated representation is then passed through one or more dense layers, followed by a final classification layer that produces the model's output.
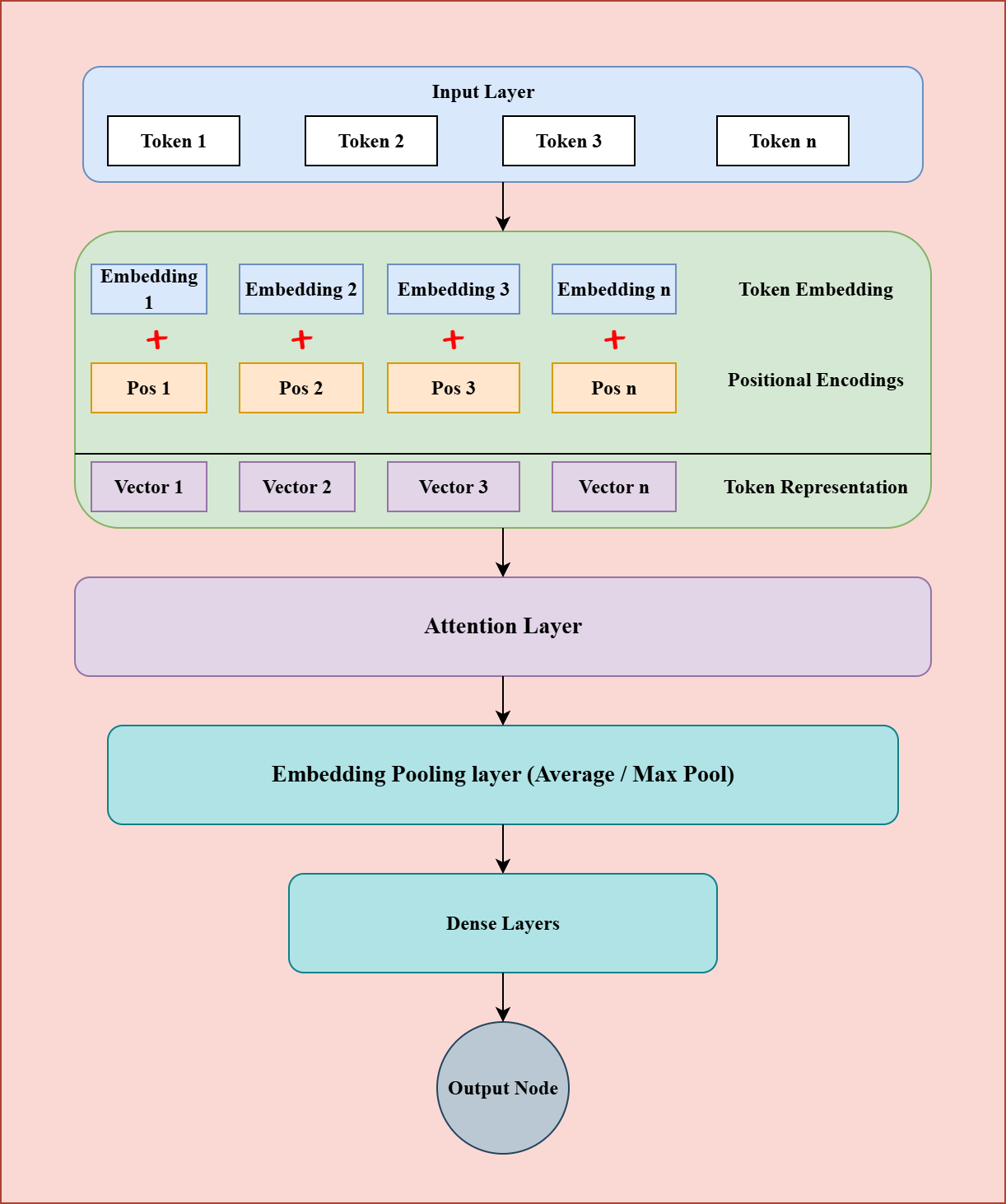
Figure 2: Attention Based Model.
What are the different types of positional encoding, and which one would you choose?
There are generally two types of positional encoding methods used in neural network architectures to incorporate information about the order of tokens in a sequence:
-
Static (Sinusoidal) Positional Encoding:
This approach was introduced in the original Transformer paper ("Attention is All You Need"). It uses sine and cosine functions of different frequencies to represent positions. These encodings are fixed and not learned during training. The main advantage is that they allow the model to generalize to sequence lengths not seen during training and reduce the number of trainable parameters. -
Learned Positional Encoding:
In this method, positional embeddings are initialized as trainable parameters and updated during the training process, similar to word embeddings. This gives the model flexibility to learn position representations that best fit the specific dataset or task.
Why can't we simply add positional encoding without including a self-attention layer?
Pooling layers tend to dilute or lose the positional information if used alone. By adding a self-attention layer, the model can first learn the relationships and dependencies between different words in a sentence. Once these interactions are captured, the pooling layer can then aggregate the most meaningful features more effectively.
Why not use multi-head attention instead of a single head?
You can certainly experiment with multi-head attention, as it allows the model to capture different types of relationships between words in parallel. However, this also increases the number of trainable parameters and computational complexity. To make an informed choice, you should perform an ablation study comparing model performance, number of attention heads, and inference latency. Based on these results, you can decide the optimal number of heads that balance accuracy and efficiency.
How do you decide the input sentence length, and can this approach handle variable-length inputs?
The attention layer typically requires a fixed input size. To determine an appropriate sequence length, you can analyze your training data by calculating the length (in tokens) of each sentence. Then, choose a cutoff based on a high percentile, say the 90th or 95th percentile. For example, if the 90th percentile is 150 tokens, it means that 90% of your sentences have <= 150 tokens. You can then set the model's maximum sequence length to 150. Sentences shorter than this length can be padded, and longer ones can be truncated to fit this limit.
2. LSTM Based Models
Another approach to incorporate sequential information is to use an LSTM-based model. In this setup, the output from the embedding layer is passed through an LSTM layer, which processes the input sequence step by step and generates a single vector representing the entire sentence. This vector can then be fed into one or more dense layers for classification.
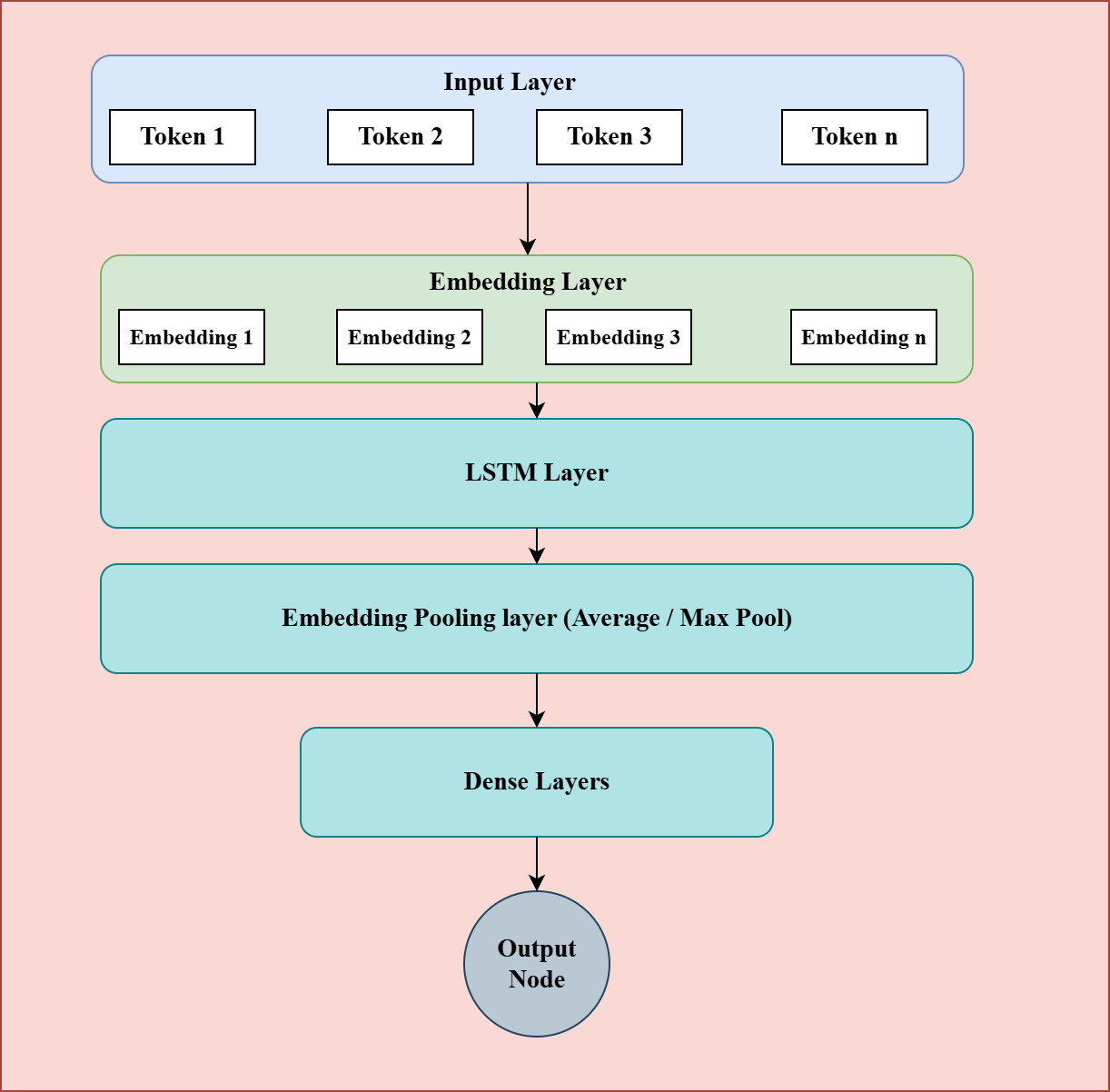
Figure 3: LSTM Based Model.
However, a key limitation of LSTM models is that their computations occur sequentially each step depends on the output of the previous one. This makes them slower during inference, especially when processing long sequences, compared to models that can process tokens in parallel, such as those using attention mechanisms.
Advance Models Such as BERT for text classification
In cases where the text classification task is more complex or nuanced, smaller models like TF-IDF, Word2Vec, or LSTM-based approaches may provide decent initial results but can quickly reach a performance plateau. To achieve higher accuracy, you can explore larger, more powerful models such as BERT.
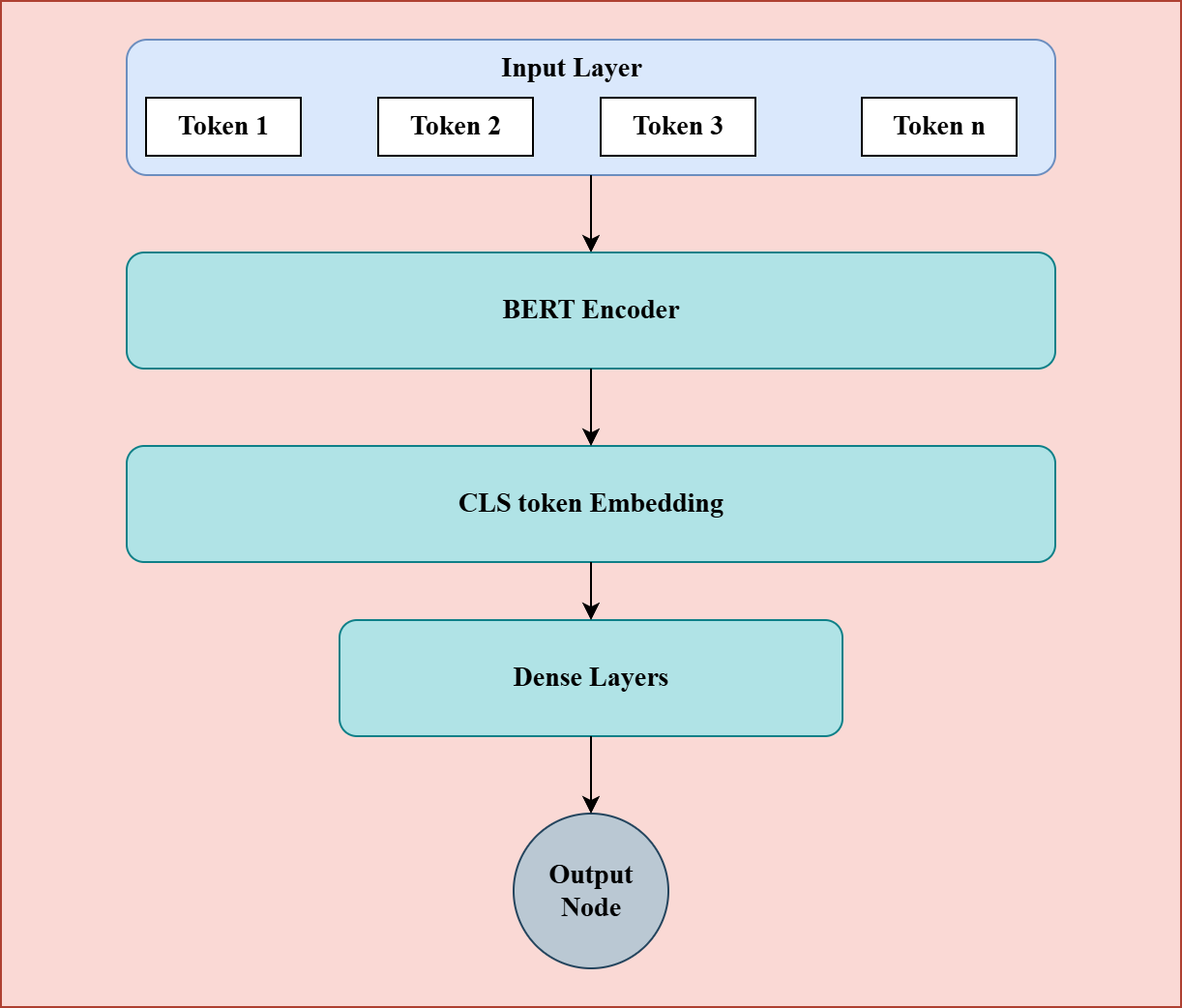
Figure 4: BERT Based Model
BERT can be used for text classification by leveraging its pretrained language understanding capabilities. You start by tokenizing the text using the BERT tokenizer and then pass the tokens through the BERT encoder. BERT outputs contextual embeddings for each token, along with a special [CLS] token that represents the overall sentence meaning. You can take the embedding of this [CLS] token, feed it into one or more dense layers, and finally add a classification layer to generate predictions.
Why do we use the [CLS] token embedding instead of taking all token embeddings, applying a pooling layer, and then feed it to classification layers?
Using the embeddings of all tokens followed by a pooling layer and dense layers is indeed a valid approach and can sometimes yield good results. However, the [CLS] token is specifically designed during BERT's pretraining phase to represent the overall meaning of the entire input sequence. During training, the [CLS] token attends to all other tokens through self-attention, effectively learning to summarize the sentence. Because of this, using the [CLS] token embedding as the sentence representation often works well in practice. That said, it's always a good idea to experiment with both methods and choose the one that gives the best performance for your specific task.
Should you fine-tune the entire BERT model or only the dense layers?
That depends on the size of your training dataset. If you have a sufficiently large amount of labeled data typically around 20,000 to 30,000 examples or more you can fine tune the entire BERT model. This allows the model to adjust its internal representations more closely to your specific task.
However, if your dataset is relatively small, it's generally better to freeze the BERT layers and fine-tune only the dense layers on top. This approach helps prevent overfitting and still leverages the powerful pretrained representations learned by BERT.
| Model | Model Performance | Inference Time | Model Size |
|---|---|---|---|
| TF-IDF | Low | Very low | Very low |
| Word2Vec with pooling | Average | Moderate (<10ms) | Low |
| Word2Vec with attention layer | Likely to be high | Moderate (10 - 20ms) | Low - Moderate |
| LSTM based Model | Likely to be high | Moderate (15 - 50ms) depending on number of LSTM layers |
Low - Moderate |
| BERT | Likely to be highest | Moderately high (50 - 100ms) | Moderately high |