Model Deployment
The two-tower model consists of three components:
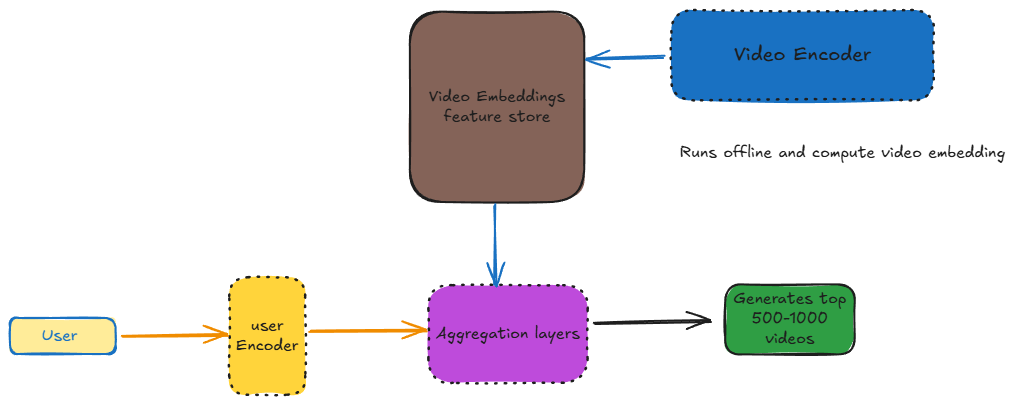 When a user comes in, we first compute the user features, then call the user encoder, which generates the user embedding. Video embeddings are pre computed and stored in video feature store. User and video embeddings are then passed to the aggregation layer to compute the final score.
When a user comes in, we first compute the user features, then call the user encoder, which generates the user embedding. Video embeddings are pre computed and stored in video feature store. User and video embeddings are then passed to the aggregation layer to compute the final score.
- User feature encoder
- Video encoder
- Aggregation layer (dense layers)
Advantages of this Architecture
- Individual components resource scaling can be done. User encoder and aggregation layers can be allocated more resources , while the video encoder can run offline which will precomputed embeddings.
- This reduces the memory footprint of the online model. video encoder is of biggest size which is deployed in offline mode.
- Parallelization of score computation is possible, which helps maintain low latency.
Drawbacks of this Architecture
- It is a complext system. System Maintaince is challenging.
- latency due to overhead calls, although reduction in latency due to Parallelization will be more.