Model Training
Any recommendation system typically consists of three components:
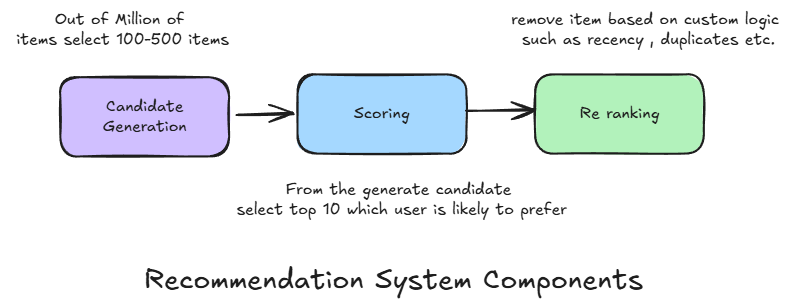
1. Candidate Generation
In this first stage, the system starts with a potentially huge corpus and generates a much smaller subset of candidates. For example, YouTube's candidate generator reduces billions of videos down to hundreds or thousands. The model must evaluate queries quickly due to the enormous size of the corpus. A single model may provide multiple candidate generators, each nominating a different subset of candidates.
-
How to train this model
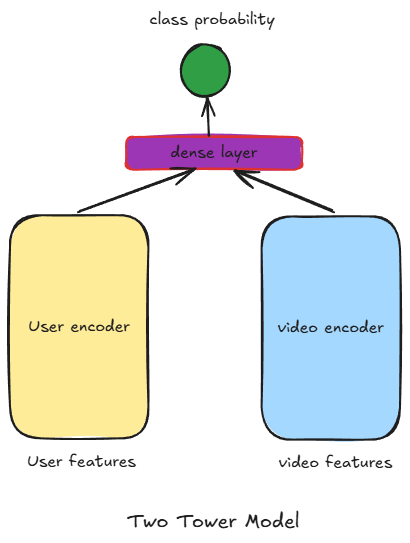
We can use a Two-Tower architecture model to train this component. The problem can be formulated as a binary classification task: whether a user has interacted with a video or not. If a user has interacted with a video, the user-video pair is labeled as 1; otherwise, it is labeled as 0.
-
Advantages of this model
- This model provides both user and video embeddings by running the respective encoders on user and video data.
- The model can be run offline on all videos to extract video embeddings using the video encoder. These embeddings can then be stored in a feature store. When a user visits, we compute user features, pass them through the user encoder to get user embeddings, and perform an Approximate Nearest Neighbor Search in the video feature store to find the most relevant videos.
- User and video embeddings generated by this model can be reused to train the Scoring model in the next step.
2. Scoring
In this stage, another model scores and ranks the candidate videos to select a final set (typically around 10) to display to the user. Since this model evaluates a relatively small subset of items, it can leverage more sophisticated algorithms and additional user/video features for higher precision.
-
How to train this model
We can extract the user and video embeddings from the Two-Tower model trained in the first step. At this stage, we can choose a more stringent objective function — for example, optimizing whether the user has watched the complete video or at least 80% of it. During inference, the model trained in the scoring step can be used to rank the candidate videos generated in the previous step, and select the top 10 most relevant ones to display.
3. Re-Ranking
Finally, the system must account for additional constraints to produce the final ranking. For example, it may remove videos that the user has explicitly disliked or boost newer content. Re-ranking also helps to ensure diversity, freshness, and fairness in the recommendations.