What Will You Learn in This Section?
- Why We Need the Random Forest Algorithm
Before diving into ensemble models, let's discuss the learning curve.
A learning curve is a plot of training and validation set error over the number of training steps.
This plot helps us understand how training and validation errors change as training progresses.
We will divide it into three regions, refer to Diagram 1.
-
Region A: Underfitting Region
This is the initial phase of training. Since training has just started, both training and validation errors are high. However, an important observation is that these errors are close to each other. This scenario is referred to as high bias (due to poor training) and low variance (since the errors are similar). This situation is known as underfitting.
-
Region C: Overfitting Region
After several training steps, the algorithm begins to fit the noise in the training dataset. As a result, its generalization ability declines, leading to high errors on the validation set. This situation is called overfitting. It is characterized by low bias (low training error) and high variance (a large difference between training and validation errors).
-
Region B: Optimal Fit
This region represents an ideal balance, low training error and low validation error. Here, the training algorithm fits the data well while maintaining strong generalization capabilities.
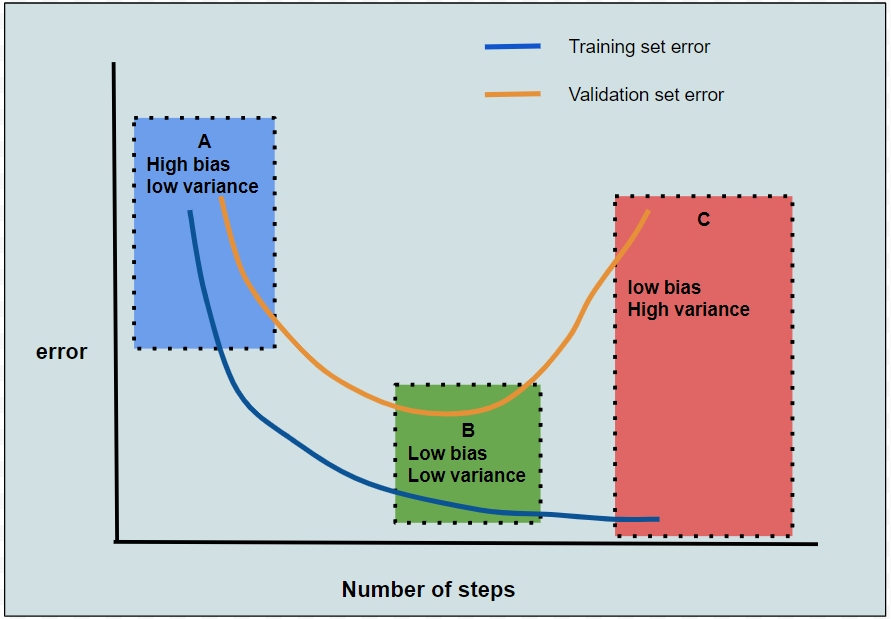
Diagram 1: Learning Curve
Overfitting Problem in Decision Tree Models
Decision trees are prone to overfitting, meaning they may attempt to make correct predictions even for noisy data,
thereby losing generalization capability.
Why does this happen?
Each leaf node in a decision tree represents a data partition. More leaf nodes mean more partitions, and the decision tree
makes separate predictions for each partition. As the number of partitions increases, the decision tree starts overfitting
the training data, leading to high errors on the validation data.
How to Prevent Overfitting in Decision Trees
Tree depth is a crucial hyperparameter in decision trees. Proper hyperparameter tuning can help mitigate overfitting.
You can find a detailed guide on hyperparameter tuning
here.
Another approach to reducing overfitting in decision trees is to use
ensemble models.
Various techniques exist within ensemble learning, one of which is
bagging.
Random Forest is an ensemble method similar to bagging that effectively addresses
the overfitting problem in decision tree algorithms.