What You Will Learn in This Section
- Details of the Random Forest Algorithm
Random Forest Algorithm
The Random Forest model is an ensemble learning method that uses the bagging technique. It trains a large number of deep decision trees in parallel and then combines their individual predictions to generate the final output.
Steps Involved in the Random Forest Algorithm
Diagram 1 illustrates the key steps involved in the Random Forest algorithm. The process consists of three major steps:
-
Bootstrap Random Sampling
This step involves creating bootstrap-sampled datasets to train individual models. These sampled datasets are independent of each other, allowing the models to focus on different parts of the training data and learn distinct patterns. The datasets are generated in parallel, reducing the overall training time.
-
Training Weak Models
In this step, multiple weak models are trained. Random Forest uses decision trees as weak models. These trees are trained in parallel on bootstrap-sampled datasets. To ensure the weak models remain uncorrelated, a random subset of features is selected at each node level. Since all weak models are trained simultaneously, the training time is significantly reduced.
-
Combining Weak Models to Make Final Predictions
The final step is to aggregate the predictions from each model to generate the final output. The following techniques are commonly used:
Combining Classification Models
The maximum voting technique is used, where each model contributes a vote, and the final predicted class is the one that receives the majority of votes.
Combining Regression Models
The final prediction is obtained by averaging the predictions of all weak models.
Can We Improve the Combination of Weak Models?
For both classification and regression problems, we can calculate the average error for each weak model. In classification, the error can be measured as the percentage of misclassified data points, while in regression, it can be the mean squared error. We can use these errors to assign weights to the individual models—giving lower weights to high-error models and higher weights to low-error models. A weighted prediction can then be computed using these weights.
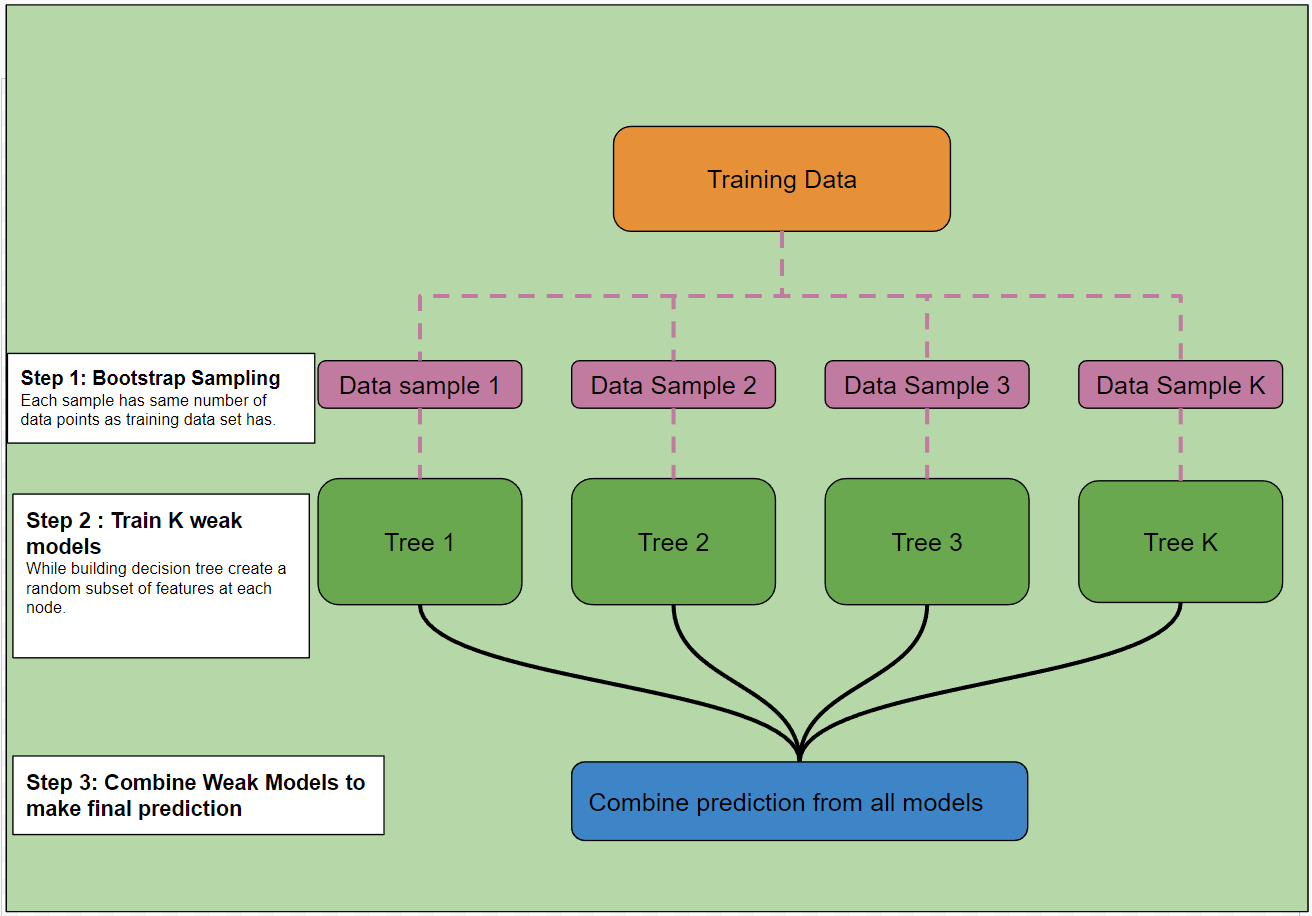
Diagram 1: Random Forest Model
The Random Forest algorithm performs best when all weak learners are uncorrelated. To achieve this, the algorithm uses two types of sampling:
-
Bootstrapped Sampling of Training Data
Instead of training all models on the same dataset, Random Forest creates a new sample for each model using bootstrap sampling (random sampling with replacement). The sampled datasets may or may not contain the same number of data points as the original training data. While this sampling technique can be tuned, it is generally preferred to keep the sample size the same as the training dataset. This ensures that individual models are trained on slightly different datasets.
-
Random Selection of Feature Subsets
While constructing individual decision trees, a random subset of features is chosen for each node split. Instead of considering all features, the algorithm selects a random subset and determines the best split from it. This corresponds to the `max_features` hyperparameter in decision trees.
These techniques ensure that weak models (decision trees) remain uncorrelated and independent of each other, enhancing the overall performance of the Random Forest algorithm.